Leonurus-free
LLM 量化方法区别 —— GPTQ、GGUF、GGML、PTQ、QAT、AWQ、AQLM
量化
量化意味着将高精度数字转换为低精度数字。低精度实体可以存储在磁盘上的小空间中,从而减少了内存需求。现在从一个简单的量化示例开始,带大家直观的理解一下这个概念。
量化的简单示例:
假设你有25个以 FP16 格式显示的权重值,如下所示的矩阵:

我们需要对这些值进行 int8 量化。下面是具体步骤:
- 旧范围 = FP16 格式中的最大权重值 - FP16 格式中的最小权重值 = 0.932–0.0609 = 0.871
- 新范围 = Int8 包含从 -128 到 127 的数字。因此,范围 = 127-(-128) = 255
- 比例 (Scale) = 新范围中的最大值 / 旧范围中的最大值 = 127 / 0.932 = 136.24724986904138
- 量化值 = 四舍五入(比例 * 原始值)
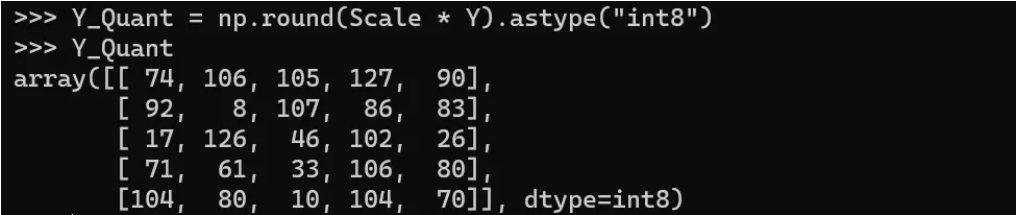
- 反量化值 = 量化值 / 比例

- 四舍五入误差 — 这里需要注意的一个重要点是,当我们反量化回到 FP16 格式时,可以看到到数字似乎并不完全相同。第一个元素 0.5415 变成了 0.543。大多数元素都会出现相同的问题。这是量化 - 反量化过程的结果所导致的误差。
1. GPT-Q:GPT模型的训练后量化
GPTQ 是一种针对4位量化的训练后量化 (PTQ) 方法,主要关注GPU推理和性能。
该方法的思想是通过将所有权重压缩到4位量化中,通过最小化与该权重的均方误差来实现。在推理过程中,它将动态地将权重解量化为float16,以提高性能,同时保持内存较低。
具体操作包括以下几个步骤:
缩放:将输入张量x除以缩放因子scale。这一步是为了将x的值范围调整到预期的量化范围。
四舍五入:将缩放后的结果四舍五入到最近的整数。这一步是为了将x的值离散化,即将其转换为整数。
限制范围:使用torch.clamp函数将四舍五入后的结果限制在0和maxq之间。这一步是为了确保量化后的值不会超出预期的量化范围。
反缩放:将量化后的张量减去零点zero,然后乘以缩放因子scale。这一步是为了将量化后的值恢复到原始的值范围。
关于GPTQ的关键点:
- GPTQ可以在大约四个GPU小时内量化具有1750亿参数的GPT模型,将位宽减少到每个权重的3或4位,与未压缩的基线相比,准确性降低可以忽略不计。
- 该方法的压缩增益是以前提出的一次性量化方法的两倍多,保持了准确性,使我们首次能够在单个GPU内执行1750亿参数的模型进行生成推断。
- GPTQ还表明,即使在极端量化情况下,也可以提供合理的准确性,其中权重被量化为2位甚至三元量化级别。
- 该方法可以用于端到端推断加速,相对于FP16,使用高端GPU(NVIDIA A100)时约为3.25倍,使用更经济实惠的GPU(NVIDIA A6000)时为4.5倍。
- GPTQ是首个表明可以将具有数百亿参数的极度准确的语言模型量化为每个组件3-4位的方法。之前的后训练方法只能在8位时保持准确,而之前的基于训练的技术只处理了比这小一个到两个数量级的模型。
GPTQ 是最常用的压缩方法,因为它针对 GPU 使用进行了优化。如果你的 GPU 无法处理如此大的模型,那么从 GPTQ 开始,然后切换到以 CPU 为重点的方法,如 GGUF是非常值得的。
2. GGUF | GGML
GGUF是GGML的新版本。尽管 GPTQ 在压缩方面表现出色,但如果你没有运行它所需的硬件,它对 GPU 的依赖性可能会成为一个缺点。
GGUF是一种量化方法,是LLM库的C++复制品,支持多种LLM,如LLaMA系列和Falcon等。它允许用户在 CPU 上运行 LLM,同时将其部分层次转移到 GPU 上以加速运行。尽管使用 CPU 通常比使用 GPU 进行推理要慢,但对于在 CPU 或 Apple 设备上运行模型的人来说,这是一种非常好的格式。特别是我们看到出现了更小、更强大的模型,如 Mistral 7B,GGUF 格式可能会成为一种常见的格式
它提供了从2到8位精度的不同级别的量化。我们可以获取原始的LLaMA模型,将其转换为GGUF格式,最后将GGUF格式量化为较低的精度。
3. PTQ 训练后量化(Post-Training Quantization) [2]
PTQ是一种常用于深度学习领域的量化技术。它的基本原理是在模型训练后,通过对模型进行量化,将模型的浮点数权重和激活转换为较低精度的表示,从而减小模型大小和计算复杂度,同时保持模型的精度损失较小。PTQ方法分为两类:只量化模型权重的方法和同时量化权重和激活的方法,像后面要说的AQLM就是第一类方法
4. QAT 训练感知的量化(Quantization Aware Training)[3]
QAT 的基本思想是根据该层权重的精度将输入量化为较低的精度。QAT 还负责在下一层需要时将权重和输入相乘的输出转换回较高的精度。这个将输入量化为较低精度,然后将权重和输入的输出转换回较高精度的过程也称为“伪量化节点插入”。这种量化被称为伪量化,因为它既进行了量化,又进行了反量化,转换成了基本操作。
QAT在训练过程中模拟量化,让模型在不损失精度的情况下适应更低的位宽。与量化预训练模型的训练后量化(PTQ)不同,QAT涉及在训练过程本身中量化模型。QAT过程可以分解为以下步骤:
- 定义模型:定义一个浮点模型,就像常规模型一样。
- 定义量化模型。定义一个与原始模型结构相同但增加了量化操作(如
torch.quantization.QuantStub())和反量化操作(如torch.quantization.DeQuantStub())的量化模型。 - 准备数据。准备训练数据并将其量化为适当的位宽。
在 QAT 中,主要对不会导致参数量化后精度损失过大的层进行量化。那些参数被量化时会对精度产生负面影响的层将保持不变量化。
5. AWQ 激活感知的权重量化(Activation-aware Weight Quantization)[4]
AWQ是一种类似于 GPTQ 的量化方法。AWQ 和 GPTQ 之间有几个区别,但最重要的区别是 AWQ 假设并非所有权重对 LLM 的性能都同等重要。
换句话说,在量化过程中,不会对所有权重进行量化;相反,只会量化对于模型保持有效性不重要的权重。因此,他们的论文提到与 GPTQ 相比,它们在保持类似甚至更好性能的同时实现了显著的加速。
该方法仍然相对较新,并且尚未像 GPTQ 和 GGUF 那样被广泛采用,因此很有趣的是看到所有这些方法是否可以共存。
另外,该方法在GPU还是CPU都可以。
量化过程:
- 校准:向预训练的LLM传递样本数据,以确定权重和激活的分布。
- 确定重要的激活和相应的权重。
- 缩放:将这些关键实体放大,同时将其余权重量化为较低精度。
- 这样做可以将由于量化而引起的准确性损失降到最低,因为这是在放大最重要的权重,同时降低不重要权重的精度。
6. AQLM (Additive Quantization LM) [5]
增量语言模型量化(AQLM)于2024年2月发布,已经集成到了HuggingFace中。现有的仅权重量化算法在技术上可以将模型权重量化到2位范围。然而,它们未能有效地保持模型的准确性。AQLM是一种新的仅权重后训练量化(PTQ)算法,为2比特/每参数范围设定了新的技术水平。与现有方法相比,它还提供了更小的基准改进,适用于3位和4位范围。具体来说,AQLM优于流行的算法如GPTQ,以及更近期但较不知名的方法如SpQR和QuIP#。
7. 总结:
将量化模型的权重内存占用减少为LLM推理带来了四个主要优点:
- 减少模型服务的硬件需求:量化模型可以使用更便宜的GPU进行服务,甚至可以在消费者设备或移动平台上进行访问。
- 为KV缓存提供更多空间,以支持更大的批处理大小和/或序列长度。
- 更快的解码延迟。由于解码过程受内存带宽限制,减少权重大小的数据移动直接改善了这一点,除非被解量化的开销抵消。
- 更高的计算与内存访问比(通过减少数据移动),即算术强度。这允许在解码期间充分利用可用的计算资源。
现在,说回到 huggingface,除了上面说的几个典型的量化方法,还有一些常见的量化格式和选择,这里也一并科普下:
- EXL2:一种新的量化格式,它在机器学习领域,特别是在大型语言模型(LLMs)在消费级GPU上的运行中代表了一个重要的进步。它作为ExLlamaV2库的一部分被引入,以其对量化的多样化方法而突出。与传统方法不同,它支持一个从2位量化开始的范围。这种量化格式可以显著减少模型的大小并加速推断。
- H6:”H6”代表”HEAD BITS”的值为6。这就意味着在网络的”head”部分,每个权重使用6个比特进行表示。依次类推,H8代表8个比特表示,这是一种量化的参数设置,可以帮助在减少模型大小和计算复杂性的同时,保持一定的精度
- LLaMAfy / LLaMAfied:即 step-by-step to align with LLaMA’s architecture
- HQQ:半二次量化(Half-Quadratic Quantization),非常简单易行(只需要几行代码就能实现优化器)。可以在4分钟内完成对Llama2-70B模型的量化操作,HQQ的主要优势是它的速度和准确性。它可以在没有校准数据的情况下进行,这使得它可以更快地进行量化,并且其结果通常与使用校准数据的传统方法相当。